前段时间做了个在java中使用SIMD指令的性能优化验证,通过使用intel开发的新特性vector API,Java中也可以利用SIMD指令优化运算效率,Amazing!
模型训练的过程大概有以下几个:
- 数据预处理
- 特征分段
- 请求PS拉取参数
- 前向传播
- 反向传播
- 推送梯度到PS
其中步骤3和6需要和PS进行通信,训练worker机处于等待状态cpu低负载,可以多线程加速。步骤4和5是模型训练的主要步骤,需要进行大量的浮点数计算,cpu高负载,是整个训练环节中耗时最大的部分。对于浮点数计算的性能可以利用单指令多数据流进行优化,现代主流的计算机寄存器长度有128位/256位/512位,比如512位寄存器可以同时容纳16个float值,假如一次同时进行计算理论上可以获得16倍的提速。在C++中对现有代码做SIMD优化比较简单,有可用的api执行SIMD的加减乘除等代数运算,开启AVX或者SSE编译选项就可以获得性能提升。但是在java生态中会比较麻烦,java没有提供可用的Intrinsic api可以直接使用SIMD指令,java现有的解决方案有两种:
- 对于部分性能要求较高的方法,java在底层实现了SIMD优化,如System.arraycopy,但是此类方法较少可用面较小。
- JIT编译器在特定条件下会对for循环进行自动向量化编译,从而实现实现性能提升。但是自动向量化的条件要求较为严苛,如:循环增量必须为1、不能有数据依赖、不能有分支跳转、不能手动循环展开等等。
好在有一帮大神一直在致力于java的性能优化,panama项目就致力于让java也能使用上SIMD指令优化,Intel和oracle合作在panama项目中引入了开发人员可控的向量化抽象,通过定义诸如DoubleVector的向量,可借由其提供的一系列向量化Intrinsic方法,JIT负责将这些Intrinsic调用转换为当前平台CPU的SIMD指令。
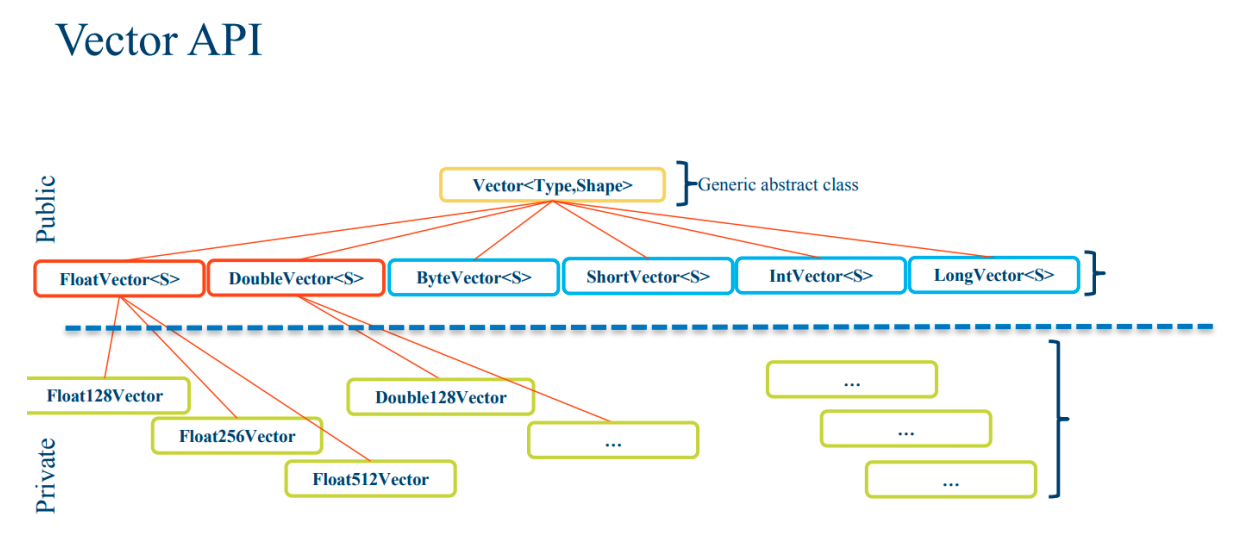
vectorApi有三个优点:
- HotSpot Intrinsic支持
- JIT即时编译映射为SIMD指令
- 避免JNI调用的额外overhead
要使用vectorApi需要编译panama项目中的源码生成定制JDK
1 | hg clone http://hg.openjdk.java.net/panama/dev/ panama-dev –b vectorIntrinsics |
简单做个向量乘法性能测试

可以看到性能提升非常显著,笔者实际中通过使用vectorApi优化的FM/DNN等模型前向和反向传播耗时可以降低到原来的八分之一(内存拷贝存在一定的overhead)
参考文献:
- Vector API Developer Program for Java* Software
- vectorApi